Memory on the harness level
· 17 min read · Comments ↓
Isn't agent memory just a bunch of markdown files with an MCP? Sometimes! But there's real nuance in how and when you store and retrieve. An interactive tour of every way agents can remember.
I met someone at an event in SF last week, and was telling them about what supermemory (my company) does — we build the context infrastructure for agents! And as soon as I said that, the first reaction was “Isn’t that just a bunch of markdown files with an MCP?”
It can be! And it’s interesting how a lot of us converge to a few simple thoughts when we think about agent memory (even the smart agent builders out there have pretty strong opinions here). A lot of this is right — we do have a markdown files product. But I don’t think there’s any one right answer for how you bring this into the harness, and that’s exactly why everyone ends up wanting to build their own memory. At supermemory we thought through each of these cases and designed the API so that any of them is possible.
When we think about “memory” in AI, the first thing that comes to mind is: you store something, you retrieve something, whenever the model needs it.
What people miss is that there’s a lot of nuance when it comes to how, and when you store and retrieve information. How do you actually bring all of this context back to the model layer? How does it differ per use case?
In this blog, we’ll explore every single way in which agents can remember and retrieve information, and all the different ways to design memory on the harness layer — and how to think about token budgets and latency tradeoffs in each different implementation.
It all comes back to the context window
Before we talk about storing anything, think about where memory actually has to land. Whatever your agent “knows” on a given turn, it knows because it’s sitting in one finite place, the context window. Your system prompt, your tool definitions, whatever you retrieved, and the conversation so far are all competing for the same fixed token budget.
So when you’re designing memory, you’re really designing a budget, and there are only two things you ever spend: the tokens a strategy occupies in that window, and the latency it adds to the turn the user is waiting on. Every decision below is some split of those two. This also determines the quality of your system!
Part 1: Remembering
There are two ways in which a model can remember something: it can be told to, or it can be watched. Explicit memory lives on the agent thread as a tool call. Implicit memory lives off to the side, where an observer does the work.
Explicit (“tool-call based”) approach
A model can explicitly choose to remember something, using tool calls. This approach is not too bad — the main loop handles memory, and it’s cheaper on many ends (slightly expensive for the main loop, cheaper to store since there’s no other model). The model gets two extra tools, remember() and recall(): remember() writes a fact, and recall() reads the store back into the window.
The agent thread owns memory here. That keeps it dead simple, and it’s why the whole thing taxes every turn and never garbage-collects itself.
Pros
- There’s no external inference that comes into play, and this is really simple to build.
- A simple vector store or KV is all you need for this.
Cons
- Because the model doesn’t know what’s already inside, this is a blind write by default. It cannot update, infer or evolve on past knowledge easily.
- This may block the main agent thread, and the agent has to be forced to “remember” things (Many harnesses and models really don’t like to do that)
- Since it’s impossible to know what will be useful in the future, this will inevitably lead to a lot of loss in the knowledge. (This is fine in many use cases!). This is also bad for “inferring” facts over time.
- The tool calls themselves are part of the context - which may confuse smaller models and inefficient in longer sessions.
And explicit is not the weak option, it’s the right one in the right place. A coding agent or a research agent is already grinding through a long loop, so it can afford to recall() first, read through the past context, and do an informed write that updates what’s already there instead of blindly appending. That extra lookup just disappears into a loop that’s already running, so the “blind write” problem mostly isn’t one for them.
Where it falls apart is the personal assistant. When someone is sitting there waiting on a reply, you can’t spend a round trip reading memory back before you write it, so you’re stuck with the naive blind writes, and every remember() is tax on a turn someone is watching. It’s too slow for the hot path, and it doesn’t feel natively “human” either — I don’t think humans choose to remember everything they do; it feels more implicit, with some explicit aspect in play.
Implicit (“observational”) approach
Many memory systems have a model built-in that is able to observe and “arrange” knowledge for future use (like OpenAI does). Or maybe run a “dreaming job” and arrange all this information at night (like Claude/Openclaw does).
The memory tools disappear from the tool block entirely. An observer (and maybe a nightly dreaming job) watches the transcript out of band and keeps one consolidated profile correct, so the agent just reads a small, fresh slice. The expensive part still costs inference, it’s just shoved off the critical path instead of sitting on the turn the user is waiting for.
Pros
- The whole write happens off the hot path, so the turn the user is waiting on never pays for it.
- The store stays consolidated and current. Contradictions get reconciled and facts get updated in place, so what the agent reads back is small and correct.
- No memory tools sit on the agent thread, which keeps the main loop simple and stops smaller models from getting confused by extra tools.
Cons
- It costs real inference. The observer has to reason over the transcript (often a lot of it) every time it folds in something new, and that gets expensive as the history grows.
- There are more moving parts to run and keep in sync: a second model, a consolidation pipeline, and the store behind it.
- Freshness is eventually-consistent. If consolidation runs out of band or only at night, the profile can lag what just happened in the conversation.
- Building the observer well is its own hard problem, since deciding what to keep, how to merge, and when to forget is most of the difficulty.
Same conversation, two windows
Here’s the same conversation assembled into a real context window. Click through the turns and watch how memories get formed and what actually lands in the context. Each remember() takes a beat to land, the same way a real tool call does. Keep an eye on the store on the left versus the profile on the right.
This is where the difference stops being abstract. With Explicit, the memory block just keeps growing, and by the last turn it’s carrying both “user is vegetarian” and “user eats fish” at the same time, because we had no idea those conflicted at write time (solvable, of course, the demo just shows the naive version). With Implicit, the same facts collapse into one diet line that gets rewritten in place when you say you eat fish now, instead of a contradiction piling up next to the old fact.
Same conversation, different shape. In the explicit case memory lives on the agent thread and every remember() is spending tokens in the hot path; in the implicit case it’s off the critical path entirely. That positioning is the whole game.
Where each strategy lands
We already named the two things you’re ever trading: how much token budget a strategy eats, and how much latency it adds to the turn the user is waiting on. So plot the two ways of remembering on exactly those axes. (We’ll map the recall side onto the same picture later, since the tradeoffs there are genuinely different.)
There’s no universally correct dot here. A throwaway script is perfectly happy in “no memory.” A long-lived personal assistant probably wants to live in the bottom-left, and getting there is most of what we think about at supermemory.
Part 2: Recall
Everything up to here has been about remembering, the write side. But a stored fact is useless if you can’t get it back into the window at the moment it matters. Recall is the other half, and it splits the same way remembering did: the model can go ask for it, or it can just show up.
Explicit lookup (“agentic recall”)
Same shape as explicit remembering. You give the model a tool, it decides mid-reasoning that it’s missing something, and it goes and gets it. It writes its own query, reads the result, and maybe chains another lookup off the first.
The thing that makes explicit lookup special is quality. If the model can keep pulling until it’s satisfied, then given enough tokens and enough turns, you’re almost guaranteed it ends up with the right context in front of it. It isn’t hoping a single retrieval got it right, it’s searching until it does.
This is where the fun harness tricks come in. What if you just give the agent a filesystem? Let it ls, grep, cat, write notes to disk and read them back, navigate its own memory the way you’d navigate a repo. That’s smfs.ai, memory as a filesystem the agent drives itself. Explicit recall like this, paired with implicit saving on the write side, is honestly one of the best setups we’ve found: cheap to store, high quality to read, and the model does the hard part of deciding what’s relevant.
The cost is latency, and it stacks, every lookup is a round trip and reading the result is another turn. But this is exactly the trade a coding or research agent should make. It’s already in a long loop, so a few retrieval hops disappear into work the user expects to take time, and what they buy is quality. The latency you’d never accept in a chat reply is completely fine here.
Implicit lookup (the harness brings it)
Implicit lookup is what you reach for when you want great latency. You can’t wait for the model to decide to search, so the harness searches for it. Before the model runs at all, you take the user’s message, retrieve against the store, and drop the top results into the window. The model just finds the context already sitting there, like it remembered.
One fixed hop instead of an open-ended loop. Predictable, fast, every turn. You give up some quality, since you retrieve every turn whether the message needed it or not, and what you pull is only as good as the raw message as a query. For an assistant, fast and good-enough beats slow and perfect. But it breaks in an obvious place.
Same conversation, recall side
Watch the Retrieved memory block again. With explicit lookup it only fills when the model decides to search, and stays empty on a turn like “hi.” With implicit lookup the profile is always present and the retrieved slice updates itself off the message, so “hi” still lands on something personal.
Where each strategy lands
Here’s the mirror image of Part 1. Explicit lookup sits up in the latency-heavy corner where the agents live, trading time for quality, and implicit lookup plus a profile sits in the cheap bottom-left where the assistant has to be. Same two axes, opposite corners, different jobs.
Part 3: The profile
Profiles: push, don’t pull
Both of those are pull models. The context gets fetched, on demand or automatically, in response to the message. But what if you never made the model pull at all? What if you just pushed the context in?
It’s kind of like running full context, except you keep only a subset, say the last N memories, injected every turn. You’re not searching for anything, you’re always carrying a window of what’s recent.
There’s a real problem with the naive version. The last N memories are great for short-term temporal reasoning, what we were just doing, what I said two turns ago, and pretty bad at everything else, because recent is not the same as important. It might be fine paired with a lookup tool that covers the rest. But there’s a whole category of thing the model should always know no matter how old it is: your name, that you’re vegetarian, how you like your answers. Pure recency throws that straight out.
So you actually want two kinds of pushed context. A static profile, the stuff that’s always true and always injected regardless of recency or the current message, and a dynamic profile, the part that shifts with what’s relevant right now. The way we handle this at supermemory is exactly that split, static and dynamic profiles, and more recently profile buckets, so you can push in the things that never change alongside the things that do. (More on this soon.)
Pushing N items opens its own set of knobs. What’s the right N? How do you decide what the model should always know, no matter how old it is? And how do you keep the window fresh without forgetting the things that still matter? We won’t go deep on those here, but they’re exactly the questions a good profile has to answer.
What you actually want is a profile
Step back from the mechanism for a second. What you really want is almost embarrassingly simple: a small markdown file with just the right information about the user, that the agent always knows, sitting in context on every turn with no tool call and no lookup.
Getting that markdown the naive way is expensive. You re-read the whole history and have a model rewrite the file from scratch every time anything changes, which is a pile of inference for a file that mostly stays the same between turns.
The obvious shortcut is to skip the model and just load the last N things the user said. That fails in two ways. The last N and the most important N are different sets, so a throwaway “lol nice” from five minutes ago elbows out the fact that you’re vegetarian. And the things the agent should always know, like your name, drop out of the window the moment they’re older than N.
So you need both:
- Static is what the model should always know about you: your name, that you’re a CEO, that you code all day. This barely moves.
- Dynamic is what you’ve been doing lately: the trip you’re planning, the bug you’re chasing this week. This is always in motion.
And a profile derived from those two has to be genuinely smart about it:
- it’s always fresh, reflecting the latest state of the user
- it updates itself automatically whenever anything underneath it changes
- it stays extremely small, since it’s in context on every single turn
- it’s stable enough to be prompt-cacheable, so you aren’t re-billed for it on every call
- it’s customizable, because every use case needs to remember a different shape of thing
At supermemory we get there with a custom database and a model built specifically to store everything as a fact-based rich graph, and the profile is a derivation of that graph. Most other ways of building it land in one of two bad places: too expensive (rewrite everything on every change) or too slow (compute it on the hot path). Done right the profile reads as instant, and it never touches the latency of the turn the user is waiting on.
Where it pays off: the non-literal question
The reason all of this is worth the trouble shows up on the questions retrieval can’t touch. Ask “find me the best monitor” and a pure retrieval system goes hunting for the word “monitor” in your history, finds nothing, and answers like it has never met you. The profile is already in context, so the model knows you’re a CEO who codes all day, and it can answer for you with zero literal matches in memory.
That’s the whole point. A good profile means even a question with no literal match in your history still comes back personalized.
Putting it together
None of these strategies wins on its own. Real systems mix them, and which mix you want falls out of the same two axes we kept circling back to: how much latency the user will sit through, and how much quality the task demands.
A personal assistant runs on the hot path with someone watching the reply land, so it wants the cheap, fast corner. Implicit writing keeps a profile current off the critical path, a pushed profile makes even “hi” feel personal, and implicit retrieval off the message covers the rest. Profile plus auto-retrieval is usually all it needs.
A coding agent is already grinding through a long loop, so it can afford to spend latency on quality. Explicit tool use on both sides, a recall() before an informed write, and a filesystem it drives itself (smfs.ai). The round trips disappear into work the user already expects to take time.
A research assistant lives and dies on quality, so let it keep pulling. Explicit lookup that searches, reads, and chains another query until it’s satisfied, with a scratchpad it can write intermediate findings to. Nobody minds a deep report taking a minute, so spend the latency where it buys you coverage.
A legal or compliance agent can’t afford a confident wrong answer, so precision and provenance beat speed. Explicit retrieval with citations back to the source, informed writes rather than blind appends, and a profile that pins down the matter and the client. Slow and exactly right wins over fast and roughly right.
A customer support agent should walk in already knowing who it’s talking to. Push the customer’s profile and recent tickets every turn, retrieve implicitly off the message for the rest, and you get fast replies that still sound like they remember the account.
A voice agent has the tightest latency budget of all, because every retrieval hop is audible dead air on a live call. You can’t send it off to search mid-sentence, so it leans almost entirely on what’s already in the window: a pushed profile carries who the caller is, and a single implicit retrieval off the last thing they said covers the rest. This is where profiles matter most. A voice assistant that has to pause and look you up has already lost the conversation, so the context has to be sitting there before the words even arrive.
A throwaway script remembers nothing, and that’s the right call.
Once you can see each strategy as a position on those two axes, picking the right combination for your agent stops being guesswork. That’s the whole job, and it’s what we spend our days on at supermemory.
How we do all this at supermemory
Everything in this post is a position on those two axes, and the reason supermemory exists is so you don’t have to rebuild each one from scratch. We support the explicit path and the implicit path, and you can mix them however your harness needs.
A lot of the pieces we’ve talked about are already built in:
- Profiles that manage themselves. Static and dynamic profiles, and profile buckets, that stay fresh on their own. They update as new things land, reconcile contradictions instead of stacking them, and stay small enough to sit in context every turn and stable enough to prompt-cache. You never rebuild the markdown by hand.
- Dreaming. An observer that watches your data and connects the dots out of band, so the profile keeps getting better while nobody’s waiting on it. We wrote about dynamic dreaming here.
- A filesystem. Agentic retrieval where the model drives its own memory like a repo, which we found makes retrieval 55% cheaper and more accurate. That’s smfs.
- Forgetting, on purpose. Memories decay and the facts that stop mattering fall away, so the window doesn’t silently fill up with stale context you’re still paying for.
- The context cloud. The infrastructure underneath all of it, built to be cheap enough that none of this has to be a luxury. Here’s how we got the cost down.
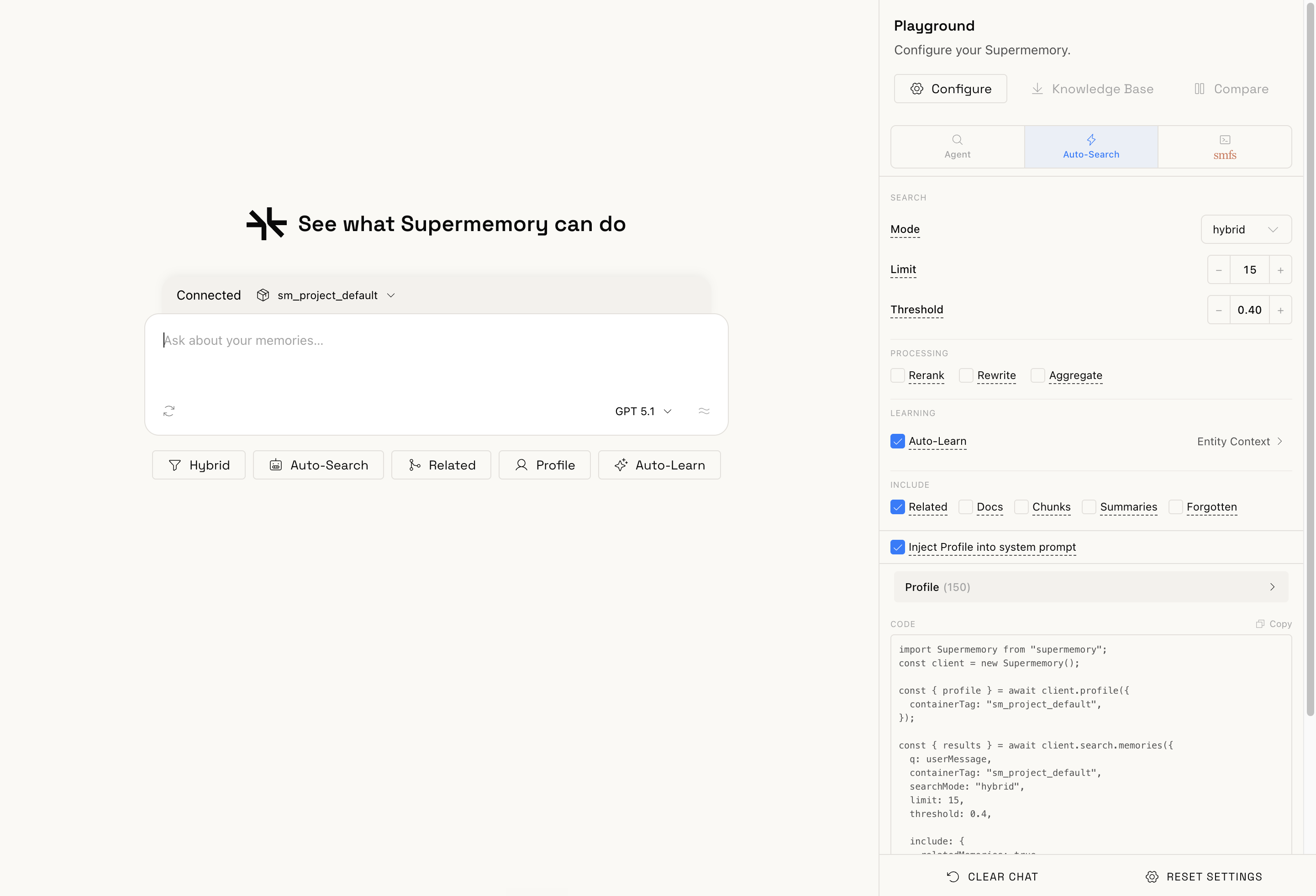
It’s fully customizable, for every harness. You decide what gets remembered, how it’s retrieved, and what gets pushed into the window, and every one of those is a knob you can turn. Flip the strategies from this post and watch the call rewrite itself:
That’s a slice of it. The real playground exposes even more (docs, related and forgotten memories, query rewriting, reranking, entity context, profile injection, and so on), live against your own data.
This is the substrate, and what we actually want is for you to build the best context system for your agent on top of it.